한글 토크나이징 라이브러리
해당 포스팅의 내용은 텐서플로2와 머신러닝으로 시작하는 자연어 처리를 보고 개인적으로 정리한 내용입니다.
자연어 처리에서 각 언어마다 모두 특징이 다르기 때문에 천편일률적으로 동일한 방법을 적용하는데에는 어려움이 있다. 한글에도 NTLK나 Spacy 같은 도구를 사용할 수 있으면 좋겠지만 언어 특성상 영어를 위한 도구를 사용하기에는 적합하지 않다. 예를 들어 영어에는 없는 혀앹소 분석이나 음소 분리와 같은 내용은 앞의 라이브러리로는 처리하기 어렵다. 이러한 처리를 위한 도구로 KoNLPy라는 것이 있다. KoNLPy는 형태소 분석으로 형태소 단위의 토크나이징을 가능하게 할뿐만 아니라 구문 분석을 가능하게 해서 언어 분석을 하는 데 유용한 도구이다.
KoNLPy
KoNLpy는 한글 자연어 처리를 쉽게 간결하게 할 수 있도록 만들어진 오픈소스 라이브러리이다. 또한 국내에 이미 만들어져 사용되고 있는 여러 형태소 분석기를 사용할 수 있게 허용한다.
설치
KoNLPy의 경우 기존의 자바로 쓰여진 형태소 분석기를 사용하기 때문에 사용 중인 PC에 1.7이상 버전의 자바(Java)가 설치돼어 있어야 한다. 윈도우라면 cmd를 이용하고 리눅스 환경이라면 커맨드라인에 아래와 같이 설치되어 있는 자바 버전을 확인할 수 있다. (따로 Java에 대한 설치방법을 이 포스팅에 설명해놓지 않겠다.)
!java -version
>> Output
openjdk version "1.8.0_275"
OpenJDK Runtime Environment (build 1.8.0_275-8u275-b01-0ubuntu1~18.04-b01)
OpenJDK 64-Bit Server VM (build 25.275-b01, mixed mode)
이후 아래와 같이 KoNLPy를 설치해준다.
pip install konlpy
import konlpy
별다른 오류없이 import가 성공한다면 설치가 완료된 것이다.
형태소 단위 토크나이징
한글 텍스트의 경우에는 형태소 단위 토크나이징이 필요할 때가 있다. KoNLPy에서는 여러 형태소 분석기를 제공하며, 각 형태소 분석기는 클래스 형태로 되어 있고, 이를 객체로 생성한 후 메서드를 호출하여 토크나이징할 수 있다.
형태소 분석 및 품사 태깅
형태소 분석을 설명하기 전에 먼저 형태소가 무엇인지 알아보자. 형태소란 의미를 가지는 가장 작은 단위로서 더 쪼개지면 의미를 상실하는 것들을 말한다. 따라서 형태소 분석이란 의미를 가지는 단위를 기준으로 문장을 살펴보는 것을 의미한다. KoNLPy 이전에 C,C++ 혹은 Java등으로 작성된 형태소 분석을 할 수 있는 좋은 라이브러리들이 있었고 KoNLPy는 이러한 기존의 형태소 분석기들을 파이썬의 라이브러리로 통합해서 사용할 수 있게 해주었다. KoNLPy에 포함된 형태소 분석기들을 객체 형식으로 포함되어 있으며 그 목록은 아래와 같다.
- Hannanum
- Kkma
- Komoran
- Mecab
- Okt(Twitter)
위 객체들은 모두 동일하게 형태소 분석 기능을 제공하는데, 각기 성능이 조금씩 다르므로 직접 비교해보고 자신의 데이터를 가장 잘 분석하는 분석기를 사용하면 된다.
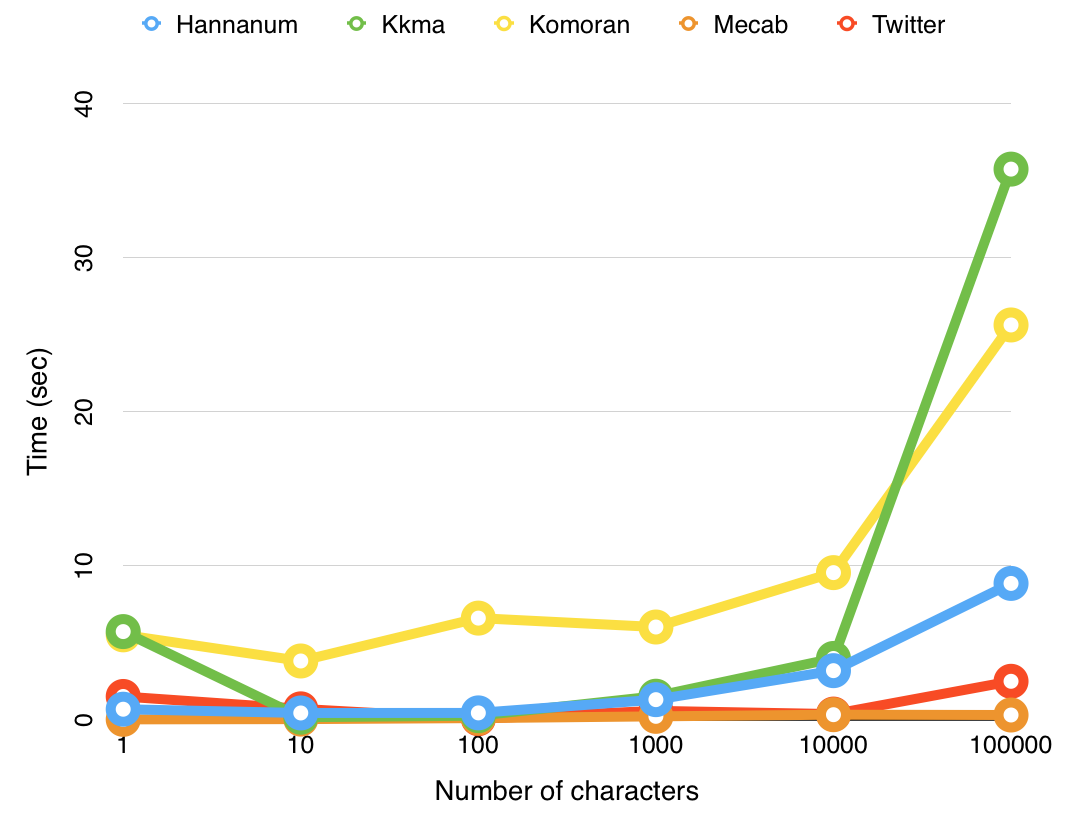 KoNLPy의 각 형태소 분석기의 성능 비교
KoNLPy의 각 형태소 분석기의 성능 비교
Mecab의 경우 윈도우에서는 사용할 수 없다. Okt의 경우 원래 이름이 Twitter였으나 0.5.0 버전 이후로는 이름이 Okt로 바뀌었다. 이 포스팅에서는 Ock를 사용하도록 하겠다. Ock를 사용하기 위해서는 먼저 불러와야 한다.
from konlpy.tag import Okt
그리고 객체를 생성해준다.
okt = Okt()
okt 객체는 다음과 같은 4가지의 함수를 제공한다.
-
okt.morphs() : 텍스트를 형태소 단위로 나눈다. 옵션으로는
norm과stem이 있다. 각각 True 혹은 False 값을 받는다.norm은normalize의 약자로서 문장을 정규화하는 역할을 하고,stem은 각 단어에서 어간을 추출하는 기능이다. 기본값은 둘다 False 이다. -
okt.nouns() : 텍스트에서 명사만 뽑아낸다.
-
okt.phrases() : 텍스트에서 어절을 뽑아낸다.
-
okt.pos() : 위의 세 함수는 어간/명사/어절 등을 추출해내는 추출기로 동작했다면
pos함수는 각 품사를 태깅하는 역할을 한다. 품사를 태깅한다는 것은 주어진 텍스트를 형태소 단위로 나누고, 나눠진 각 형태소를 그에 해당하는 품사와 함께 리스트화하는 것을 의미한다. 이 함수에서도 옵션을 설정할 수 있는데morphs함수와 마찬기지로norm,stem옵션이 있고 추가적으로join함수가 있는데 이 옵션 값을 True 로 설정하면 나눠진 형태소와 품사를 ‘형태소/품사’ 형태로 같이 붙여서 리스트화한다.
임의의 문장을 직접 지정하고 해당 문장에 각 함수를 직접 적용해 보자.
text = "한글 자연어 처리는 재밌다 이제부터 열심히 해야지ㅎㅎㅎ"
print(okt.morphs(text))
print(okt.morphs(text, stem=True)) # 형태소 단위로 나눈 후 어간을 추출
>> Output
['한글', '자연어', '처리', '는', '재밌다', '이제', '부터', '열심히', '해야지', 'ㅎㅎㅎ']
['한글', '자연어', '처리', '는', '재밌다', '이제', '부터', '열심히', '하다', 'ㅎㅎㅎ']
stem 옵션을 주어 어간 추출을 한 경우 ‘해야지’ 가 ‘하다’ 로 추출된 것을 볼 수 있다. 이제 명사와 어절을 추출해 보자.
print(okt.nouns(text))
print(okt.phrases(text))
>> Output
['한글', '자연어', '처리', '이제']
['한글', '한글 자연어', '한글 자연어 처리', '이제', '자연어', '처리']
nouns 함수를 사용한 경우는 명사만 추출됐고 phrases 함수의 경우 어절 단위로 나뉘어서 추출되었다.
이제 품사 태깅을 하는 함수인 pos 함수를 사용해 보자.
print(okt.pos(text))
print(okt.pos(text, join=True)) # 형태소와 품사를 붙여서 리스트화
>> Output
[('한글', 'Noun'), ('자연어', 'Noun'), ('처리', 'Noun'), ('는', 'Josa'), ('재밌다', 'Adjective'), ('이제', 'Noun'), ('부터', 'Josa'), ('열심히', 'Adverb'), ('해야지', 'Verb'), ('ㅎㅎㅎ', 'KoreanParticle')]
['한글/Noun', '자연어/Noun', '처리/Noun', '는/Josa', '재밌다/Adjective', '이제/Noun', '부터/Josa', '열심히/Adverb', '해야지/Verb', 'ㅎㅎㅎ/KoreanParticle']
join 옵션을 True로 설정한 경우 형태소와 품사가 함께 나오는 것을 볼 수 있다.
KoNLPy 데이터
KoNLPy 라이브러리는 한글 자연어 처리에 활용할 수 있는 한글 데이터를 포함하고 있다. 따라서 라이브러리르 통해 데이터를 바로 사용할 수 있으며, 데이터의 종류는 다음과 같다.
-
kolaw : 한국 법률 말뭉치. ‘constitution.txt’ 파일로 저장되어 있다.
-
kobill : 대한민국 국회 의안 말뭉치. 각 id 값을 가지는 의안들로 구성돼 있고 파일은 ‘1809809.txt’로부터 ‘1809899.txt’까지로 구성되어 있다.
각 데이터를 불러와보자.
from konlpy.corpus import kolaw
from konlpy.corpus import kobill
이후 법률 말뭉치를 먼저 불러와보자. 긴 말뭉치이므로 앞의 20개까지만 불러와 보자.
kolaw.open('constitution.txt').read()[:20]
>> Output
'대한민국헌법\n\n유구한 역사와 전통에 '
국회 의안 말뭉치도 불러와보자. 여러 의안 중에 ‘1809890.txt’ 의안을 불러온다. 역시 긴 말뭉치이므로 앞의 50개까지만 불러와 보자.
kobill.open('1809890.txt').read()[:50]
>> Output
'지방공무원법 일부개정법률안\n\n(정의화의원 대표발의 )\n\n 의 안\n 번 호\n\n9890\n\n발의'
위 데이터들을 여러 가지 한글 자연어 처리 문제를 연습하는 데 활용할 수 있다.
댓글남기기