자연어 처리 개요 - 단어 표현(Word Representation)
해당 포스팅의 내용은 텐서플로2와 머신러닝으로 시작하는 자연어 처리를 보고 개인적으로 정리한 내용입니다.
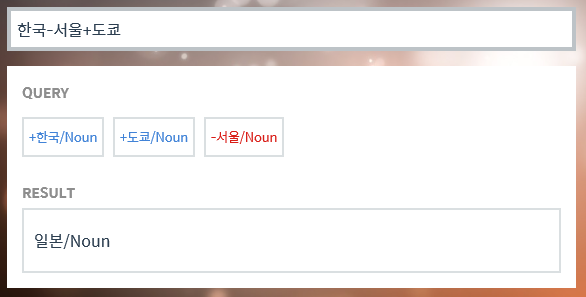
위 사이트는 한국어 단어에 대해서 벡터 연산을 해볼 수 있는 사이트이다. 위 사이트에서는 단어들(실제로는 Word2Vec 벡터)로 더하기, 빼기 연산을 할 수 있다. 예를 들어 아래의 식에서 좌변을 집어 넣으면, 우변의 답들이 나온다.
- 고양이 + 애교 = 강아지
- 한국 - 서울 + 도쿄 = 일본
- 박찬호 - 야구 + 축구 = 호나우두
단어가 가지고 있는 어떤 의미들을 가지고 연산을 하고 있는 것처럼 보인다. 이런 연산이 가능한 이유는 각 단어 벡터가 단어 간 유사도를 반영한 값을 가지고 있기 때문이다. 이번 포스팅에서는 어떻게 이것들이 가능한지에 대해 작성해 보고자 한다.
단어 표현
자연어 처리는 컴퓨터가 인간의 언어를 이해하고 분석 가능한 모든 분야를 말한다. 따라서 자연어 처리의 기본적인 문제는 ‘어떻게 자연어를 컴퓨터에게 인식시킬 수 있을까?’다. 먼저 컴퓨터가 텍스트를 인식하는 기본적인 방법들을 알아보자.
 ‘미안하다’는 단어의 시각적 표현
‘미안하다’는 단어의 시각적 표현
컴퓨터는 텍스트뿐만 아니라 모든 값을 읽을 때 이진화된 값으로 이해한다.
- ‘언’ : 1100010110111000
- ‘어’ : 1100010110110100
하지만 자연어 처리에 이러한 방식을 그대로 적용하기는 무리가 있다. 문자를 이진화한 값의 경우 언어적인 특성이 전혀 없이 컴퓨터가 문자를 인식하기 위해 만들어진 값이므로 자연어 처리를 위해 만드는 모델에 적용하기에는 부적합하다.
이러한 질문의 답을 찾는 것이 단어 표현(Word Representation) 분야다. 텍스트를 자연어 처리를 위한 모델에 적용할 수 있게 언어적인 특성을 반영해서 단어를 수치화하는 방법을 찾는 것이다. 앞선 포스팅에서 본 것처럼 단어를 수치화할 때는 단어를 주로 벡터로 표현한다. 따라서 단어 표현은 단어 임베딩(Word Embadding) 혹은 단어 벡터(Word Vector)로 표현하기도 한다.
원-핫 인코딩(One-Hot Encoding)
단어를 표현하는 가장 기본적인 방법은 원-핫 인코딩(One-Hot Encoding) 방식이다. 단어를 하나의 벡터로 표현하는 방법인데 각 값은 0 혹은 1의 값만 갖는다. 머신러닝을 공부해보았다면 익숙한 방식일 것이다. 이름에서 알 수 있는 벡터 값 가운데 하나만 1이라는 값을 가지고 나머지는 모두 0 값을 가지는 방식이다.
예를 들어 6개의 단어(남자, 여자, 아빠, 엄마, 삼촌, 이모)를 알려줘야 한다고 했을 때 원-핫 인코딩 방식으로 표현한다고 하면
- 아빠 : [0, 0, 1, 0, 0, 0]
- 이모 : [0, 0, 0, 0, 0, 1]
이런 식으로 될 것이다. 방법 자체가 매우 간단하고 이해하기도 쉽지만 이 방법에는 결정적인 두 가지 문제점이 존재한다. 위의 예시에는 총 6개의 단어만 표현하면 되었지만 실제 자연어 처리 문제를 해결할 때는 수십만, 수백만 개가 넘는 단어를 표현해야 한다. 이 경우 각 단어 벡터의 크기가 너무 커지기에 공간을 많이 차지하고, 큰 공간에 비해 실제 사용되는 값은 1이 되는 값 하나뿐이므로 매우 비효율적이다. 또 다른 문제점은 이러한 표현 방식은 단순히 단어가 뭔지만 알려 줄 수 있고, 벡터값 자체에는 단어의 의미나 특성 같은 것들이 전혀 표현되지 않는다는 것이다.
이렇게 벡터 또는 행렬(matrix)의 값이 대부분이 0으로 표현되는 방법을 희소 표현(sparse representation)이라고 한다. 그러니까 원-핫 벡터는 희소 벡터(sparse vector)이다.
이런 단어 벡터의 크기가 너무 크고 값이 희소(sparse)하다는 문제와 단어 벡터가 단어의 의미나 특성을 전혀 표현할 수 없다는 문제를 해결하기 위해 다른 인코딩 방법들이 제안되었다. 즉 벡터의 크기가 작으면서도 벡터가 단어의 의미를 표현할 수 있는 방법들인데, 이러한 방법들은 분포 가설(Distrivuted hypothesis)을 기반으로 한다.
분포 가설이란 “같은 문맥의 단어, 즉 비슷한 위치에 나오는 단어는 비슷한 의미를 가진다.” 라는 개념이다. 따라서 어떤 글에서 비슷한 위치에 존재하는 단어는 단어 간의 유사도가 높다고 하는 판단하는 방법인데 크게 두 가지 방법으로 나뉘게 된다.
ex) 강아지란 단어는 귀엽다, 예쁘다, 애교 등의 단어가 주로 함께 등장하는데 분포 가설에 따라서 저런 내용을 가진 텍스트를 벡터화한다면 저 단어들은 의미적으로 가까운 단어가 된다.
카운트 기반(Count-base) 방법
카운트 기반 방법으로 단어를 표현한다는 것은 어떤 글의 문맥 안에 단어가 동시에 등장하는 횟수를 세는 방법이다. 기본적으로 동시 등장 횟수를 하나의 행렬로 나타낸 뒤 그 행렬을 수치화해서 단어 벡터로 만드는 방법을 사용하는 방식인데, 다음과 같은 방법들이 있다.
- 특이값 분해(Singular Value Decomposition, SVD)
- 잠재의미분석(Latent Semantic Analysis, LSA)
- Hyperspace Analogue to Language(HAL)
- Hellinger PCA(Principle Component Analysis)
위의 방법들은 모두 동시 출현 행렬(Co-occurrence Matrix)을 만들고 그 행렬들을 변형하는 방식이다.
아래의 예시를 가지고 동시 출현 행렬을 만들어 보자.
- 성진과 창욱은 야구장에 갔다.
- 성진과 태균은 도서관에 갔다.
- 성진과 창욱은 공부를 좋아한다.
위의 문장들을 가지고 동시 출현 행렬을 만들면 아래와 같은 표가 만들어진다.
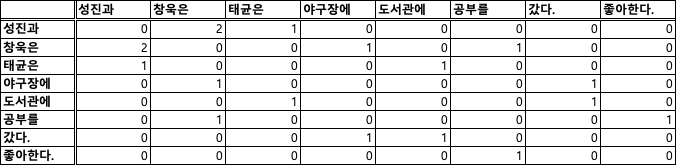
이렇게 만들어 진 동시 출현 행렬을 토대로 특이값 분해 방법 등을 사용해 단어 벡터를 만들면 된다.
이러한 카운트 기반 방법의 장점은 우선 빠르다는 점이다.(적은 시간으로 단어 벡터를 만들 수 있다.) 이러한 방법은 예측 방법에 비해 좀 더 이전에 만들어진 방법이지만 데이터가 많은 경우 단어가 잘 표현되고 효율적이여서 아직까지도 많이 사용되는 방법이다.
예측(Predictive) 방법
예측 기반 방법이란 신경망 구조 혹은 어떠한 모델을 사용해 특정 문맥에서 어떤 단어가 나올지를 예측하면서 단어를 벡터로 만드는 방식이다. 예측 방법에는 아래와 같은 것들이 있다.
- Word2vec
- NNLM(Neural Network Language Model)
- RNNLM(Recurrent Neural Network Language Model)
여러 예측 기반 방법 중에 단어 표현 방법으로 가장 많이 사용되는 Word2vec에 대해 자세히 알아보자. Word2vec은 CBOW(Continuous Bag of Words)와 Skip-Gram이라는 두 가지 모델로 나뉜다.
두 모델은 서로 반대되는 개념으로 생각하면 되는데, CBOW의 경우 어떤 단어를 문맥 안의 주변 단어들을 통해 예측하는 방법이다. 반대로 Skip-Gram의 경우에는 어떤 단어를 가지고 특정 문맥 안의 주변 단어들을 예측하는 방법이다.
예시를 들어 비교해보자.
- 창욱은 냉장고에서 음식을 꺼내서 먹었다.
이때 CBOW는 주변 단어를 통해 하나의 단어를 예측하는 모델이다. 즉 다음 문장의 빈칸을 채우는 모델이라고 생각하면 된다.
- 창욱은 냉장고에서 _____ 꺼내 먹었다.
반대로 Skip-Gram은 하나의 단어를 가지고 주변에 올 단어를 예측하는 모델이다. 다음 문장에서 빈칸을 채운다고 생각하면 된다.
- __ ___ 음식을 __ __
두 모델은 위와 같은 단어들을 예측하면서 단어 벡터를 계속해서 학습한다.
각 모델의 학습 방법에 대해 설명하면 CBOW의 경우 아래 순서로 학습한다.
- 각 주변 단어들을 원-핫 벡터로 만들어 입력값으로 사용한다.(입력측 벡터)
- 가중치 행렬(weight matrix)을 각 원-핫 벡터에 곱해서 n-차원 벡터를 만든다.(N-차원 은닉층)
- 만들어진 n-차눤 벡터를 모두 더한 후 개수로 나눠 평균 n-차원 벡터를 만든다(출력층 벡터)
- n-차원 벡터에 다시 가중치 행렬을 곱해서 원-핫 벡터와 같은 차원의 벡터로 만든다.
- 만들어진 벡터를 실제 예측하려고 하는 단어의 원-핫 벡터와 비교해서 학습한다.
Skip-Gram의 학습 방법도 비슷한 과정으로 진행한다.
- 하나의 단어를 원-핫 벡터로 만들어서 입력값으로 사용한다.(입력층 벡터)
- 가중치 행렬을 원-핫 벡터에 곱해서 n-차원 벡터를 만든다.(N-차원 은닉층)
- n-차원 벡터에 다시 가중치 행렬을 곱해서 원-핫 벡터와 같은 차원의 벡터로 만든다.(출력층 벡터)
- 만들어진 벡터를 실제 예측하려는 주변 단어들 각각의 원-핫 벡터와 비교해서 학습한다.
두 모델의 학습 과정이 비슷해 보이지만 확실한 차이점이 있다. CBOW에서는 입력값으로 여러 개의 단어를 사용하고, 학습을 위해 하나의 단어와 비교한다. Skip-gram에서는 입력값이 하나의 단어를 사용하고, 학습을 위해 주변의 여러 단어와 비교한다.
위의 학습 과정을 모두 끝낸 후 가중치 행렬의 각 행을 단어 벡터로 사용한다. 이처럼 Word2vec의 두 모델은 여러가지 장점이 있다. 기존의 카운트 기반 방법으로 만든 단어 벡터보다 단어 간의 유사도를 잘 측정한다. 또 한 가지 장점은 단어들의 복잡한 특징까지도 잘 잡아낸다는 점이다.
마지막으로 이렇게 만들어진 단어 벡터는 서로에게 유의미한 관계를 측정할 수 있다는 점인데, 예를 들어 4개의 단어(엄마, 아빠, 남자, 여자)를 Word2vec 방식을 사용해 단어 벡터로 만들었다고 하면 ‘엄마’와 ‘아빠’라는 단어의 벡터 사이의 거리와 ‘여자’와 ‘남자’라는 단어의 벡터 사이의 거리가 같게 나온다.

Word2vec의 CBOW와 Skip-gram 모델 중에서는 보통 Skip-gram이 성능이 좋다. 하지만 절대적으로 좋은 것은 아니지 두 가지 모두 상황에 따라 사용하는 것이 적절하다. 그리고 두 가지 방법을 모두 포함하는 Glove라는 단어 표현 방법 또한 자주 사용된다.
본 포스팅에서는 최대한 간략한 설명을 위해 수식 등은 생략하였으니 보다 자세한 개념 이해를 하고자 한다면 해당 링크를 정독해보길 추천한다.
댓글남기기