영어 토크나이징 라이브러리
해당 포스팅의 내용은 텐서플로2와 머신러닝으로 시작하는 자연어 처리를 보고 개인적으로 정리한 내용입니다.
자연어 처리를 위해서는 우선 텍스트에 대한 정보를 단위별로 나누는 것이 일반적이다. 이처럼 입력 정보를 특정 기본 다뉘로 자르는 것을 토크나이징이라고 한다. 파이썬에는 이러한 토크나이징을 도와주는 라이브러리를 통해 간단히 수행할 수 있다. 토크나이징을 할 때는 언어의 특성에 따라 달라지므로 영어와 한글을 나누어서 포스팅 해보고자 한다.
NTLK
영어의 경우 NLTK(Natural Language Toolkit)과 Spacy가 토크나이징에 많이 쓰이는 대표적인 라이브러리이다. 먼저 NTLK에 대해 알아보자.
설치
NLTK 라이브러리는 간단하게 pip나 anaconda를 통해 설치가 가능하다.
conda install nltk
pip install nltk
말뭉치(Corpus) 다운로드
이제 NTLK를 사용하여 영문 텍스트를 토크나이징 해보자. 하지만 그 전에 추가로 설치할 게 있다. NLTK의 경우 단순히 라이브러리만 설치한다고 해서 바로 토크나이징할 수 있는 것은 아니다.
말뭉치(corpus)라는 것을 내려받아 연동할 수 있어야 한다. 말뭉치(corpus)는 정형이나 비정형인 단어나 표현의 묶음이다. 모든 NLTK 말뭉치는 nltk.corpus 모듈에 저장되어 있다.
예를 들면 아래와 같다.
- gutenberg : <모비딕(Moby Dick)>이나 <성경> 등 구텐베르크 프로젝트(Gutenberg Project)에서 제공하는 영문 텍스트 18개
- names : 8000개의 남성과 여성의 이름 리스트
- words : 가장 빈번하게 사용하는 영어 단어 23만 5000개
- stopwords : 14개의 언어로 된 가장 많이 사용하는 불용어(stop word) 리스트. 영어로 된 리스트는 stop words.words(“english”)에 저장되어 있다. 불용어는 대부분의 분석에서 보통 삭제하는데, 텍스트 이해에 별로 기여하는 바가 없기 때문이다.
- cmudict : 카네기멜론대학교에서 만든 발음 사전으로 13만 4000개 입력 데이터가 있다. cmudict.entries()의 각 입력 데이터는 단어와 그 음절(syllables) 리스트의 튜플이다. 단어가 같더라도 다르게 발음할 수 있다. 이 코퍼스를 사용하면 발음이 같은 동음이의어(homophones)를 찾아볼 수 있다.
NLTK 말뭉치에 대한 정보를 보고 싶으면 링크를 클릭해보자.
실습은 Jupyter Notebook이나 Colab 환경이라 가정하고 아래와 같은 명령어를 통해서 말뭉치를 다운받겠다. all-corpora를 다운로드시 모든 말뭉치를 받게 된다.
punkt와 같이 특정 말뭉치만 받게 할 수도 있다.
토크나이징
토크나이징이란 텍스트에 대해 특정 기준 단위로 문장을 나누는 것을 의미한다. 예를 들면 문장을 단어 기준으로 나누거나 전체 글을 문장 단위로 나누는 것들이 토크나이징에 해당한다.(한글의 경우는 ‘ㄱ’, ‘ㄴ’, ‘ㅏ’, ‘ㅗ’ 같은 음소도 하나의 토큰이 된다) 파이썬에서는 기본적으로 간단하게 문자열을 나눌 수 있는 split()이란 함수가 존재하지만 라이브러리를 사용하면 조금 더 다양한 방법으로 간편하게 토크나이징이 가능하다.
단어 단위 토크나이징
텍스트 데이터를 각 단어를 기준으로 토크나이징 해보자. 우선 라이브러리의 tokenize 모듈에서 word_tokenize를 불러온 후 사용하면 된다.
from nltk.tokenize import word_tokenize
sentence = "Natural language processing (NLP) is a subfield of computer science, information engineering, and artificial intelligence concerned with the interactions between computers and human (natural) languages, in particular how to program computers to process and analyze large amounts of natural language data."
print(word_tokenize(sentence))
>> Output
['Natural', 'language', 'processing', '(', 'NLP', ')', 'is', 'a', 'subfield', 'of', 'computer', 'science', ',', 'information', 'engineering', ',', 'and', 'artificial', 'intelligence', 'concerned', 'with', 'the', 'interactions', 'between', 'computers', 'and', 'human', '(', 'natural', ')', 'languages', ',', 'in', 'particular', 'how', 'to', 'program', 'computers', 'to', 'process', 'and', 'analyze', 'large', 'amounts', 'of', 'natural', 'language', 'data', '.']
영어 텍스트에 대해 work_tokenize 함수에 적용 시 리스트 형태로 결과를 반환한다. 결과를 보면 모두 단어로 구분되어 있고 특수 문자의 경우도 따로 구분된다. 이렇게 별 다른 설정 없이 함수에 데이터를 적용하기만 해도 간단하게 토크나이징 된 결과를 받을 수 있다.
문장 단위 토크나이징
경우에 따라 텍스트 데이터를 우선 단어가 아닌 문장으로 나눠야 하는 경우가 있다. 데이터가 문단으로 구성되어 있을 경우 문단을 먼저 문장으로 나누고 그 결과를 다시 단어로 나눠야 할 것이다. 이 역시 NTLK의 라이브러리를 사용하면 쉽게 토크나이징이 가능하다.
from nltk.tokenize import sent_tokenize
paragraph = "Natural language processing (NLP) is a subfield of computer science, information engineering, and artificial intelligence concerned with the interactions between computers and human (natural) languages, in particular how to program computers to process and analyze large amounts of natural language data. Challenges in natural language processing frequently involve speech recognition, natural language understanding, and natural language generation."
print(sent_tokenize(paragraph))
import nltk
nltk.download('all-corpora')
nltk.download('punkt')
>> Output
['Natural language processing (NLP) is a subfield of computer science, information engineering, and artificial intelligence concerned with the interactions between computers and human (natural) languages, in particular how to program computers to process and analyze large amounts of natural language data.', 'Challenges in natural language processing frequently involve speech recognition, natural language understanding, and natural language generation.']
사용법 역시 앞서 단어 단위 토크나이징과 유사하다. 그냥 데이터를 sent_tokenize 함수에 적용시키면 된다. 결과를 보면 위의 텍스트가 2개의 문장으로 나눠진 리스트로 나온 것을 볼 수 있다.
이 뿐만 아니라 NTLK 라이브러리의 경우 토크나이징 외에도 자연어 처리에 유용한 기능을 제공한다. 대표적으로 텍스트 데이터를 전처리 할 때 경우에 따라 불용어를 제거해야 할 때가 있다. 불용어란 큰 의미를 가지지 않는 데이터를 말한다. 예를 들어 영어에서는 ‘a’, ‘the’ 같은 관사나 ‘is’와 같이 자주 출현하는 단어들을 불용어라 한다.
NTLK에는 이러한 불용어 사전이 내장되 있어서 가져다 쓰면 된다.
Spacy
Spacy도 NLTK와 같이 간단하게 텍스트를 토크나이징 할 수 있는 라이브러리이다. 주로 교육이나 연구 목적이 아닌 상업용 목적으로 만들어졌다는 점에서 NLTK와는 다른 점이라 볼 수 있겠다.
Spacy는 현재 영어를 포함한 8개 국어에 대한 자연어 전처리 모듈을 제공하고, 빠른 속도로 전처리할 수 있는 게 장점이다.
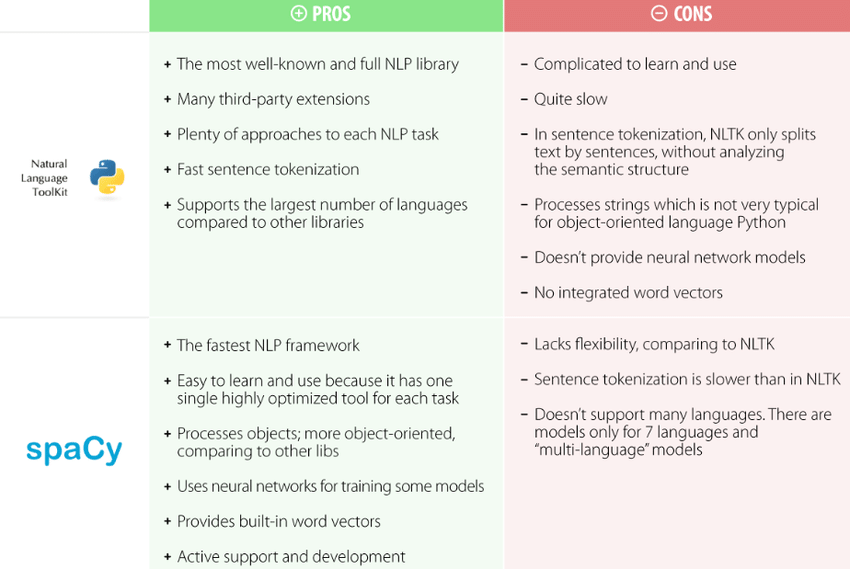 NLTK 와 Spacy 비교
NLTK 와 Spacy 비교
설치
역시 간단하다. pip나 anaconda를 이용하여 설치하자.
conda install spacy
pip install spacy
NLTK와 마찬가지로 영어에 대한 텍스트를 전처리하려면 언어 데이터 자료를 별도로 내려받아야 한다. 아래 명령어를 입력하여 ‘en’자료를 설치하자.
python -m spacy downlaod en
토크나이징
NLTK에서는 단어와 문장을 토크나이징하는 함수가 분이되어 있었지만 Spacy에서는 두 경우 모두 동일한 모듈을 통해 토크나이징 한다. 우선 라이브러리를 불러오저.
import spacy
spacy는 아래와 같이 토크나이징을 수행한다.
nlp = spacy.load('en')
sentence = "Natural language processing (NLP) is a subfield of computer science, information engineering, and artificial intelligence concerned with the interactions between computers and human (natural) languages, in particular how to program computers to process and analyze large amounts of natural language data."
doc = nlp(sentence)
먼저 spacy.load(‘en’)를 통해 토크나이징할 객체 생성 후, nlp에 할당한다. 그리고 토크나이징 할 텍스트를 sentence에 할 당후 nlp 객체에 대해 호출한다.(이 경우는 nlp 객체의 함수를 호출하는 것으로 이해하면 된다.) 그러면 입력된 텍스트에 대한 구문 분석 객체를 반환하는데 이를 doc 변수에 할당한다. 이제 이 doc 객체를 통해 단어/문장 토크나이징을 수행할 수 있다.
word_tokenized_sentence = [token.text for token in doc]
print(word_tokenized_sentence)
>> Output
['Natural', 'language', 'processing', '(', 'NLP', ')', 'is', 'a', 'subfield', 'of', 'computer', 'science', ',', 'information', 'engineering', ',', 'and', 'artificial', 'intelligence', 'concerned', 'with', 'the', 'interactions', 'between', 'computers', 'and', 'human', '(', 'natural', ')', 'languages', ',', 'in', 'particular', 'how', 'to', 'program', 'computers', 'to', 'process', 'and', 'analyze', 'large', 'amounts', 'of', 'natural', 'language', 'data', '.']
리스트 컴프리헨션을 활용하여 word_tokenized_sentence라는 단어 토크나이징의 결과 리스트를 얻었다.
sentence_tokenized_list = [sent.text for sent in doc.sents]
print(sentence_tokenized_list)
['Natural language processing (NLP) is a subfield of computer science, information engineering, and artificial intelligence concerned with the interactions between computers and human (natural) languages, in particular how to program computers to process and analyze large amounts of natural language data.']
이번에도 역시 문장 토크나이징을 수행해보았다.
NLTK는 함수를 통해 토크나이징을 처리하지만 Spacy는 객체를 생성하는 방식으로 구현되어 있다. 이처럼 객체를 생성하는 이유는 이 객체를 통해 단순히 토크나이징 뿐만 아니라 갖가지 다른 자연어 전처리 기능을 제공하기 때문이다.
댓글남기기