Requests와 BeautifulSoap를 이용한 웹 크롤링
업무를 하면서 사무자동화나 분석업무에 Python을 많이 활용하게 된다. 그 중에 가장 많이 하는것이 웹 크롤링인 것 같다. 항상 하게되지만 까먹고 구글링을 하면서 코드를 작성하는 것 같아서 기록을 해두려고 한다.
최근 상위 기관의 요청으로 보안에 취약한 카메라들(웹 페이지에서 별도의 인증과정 없이 그대로 노출되어 있는) 에 대한 조치로 바쁜일이 있었다.
조치요청을 오는 것을 보면 대다수 insecam라는 웹 사이트에서 공개되어 있던 IP카메라였기에 사전에 취약한 단말 목록을 조금 확보하고 싶었다.
먼저 해야할 것은 insecam이라는 웹 사이트에 공개되어 있는 IP카메라 중, 특정 ISP의 IP와 취약한 URI를 뽑아내는 것이였다.
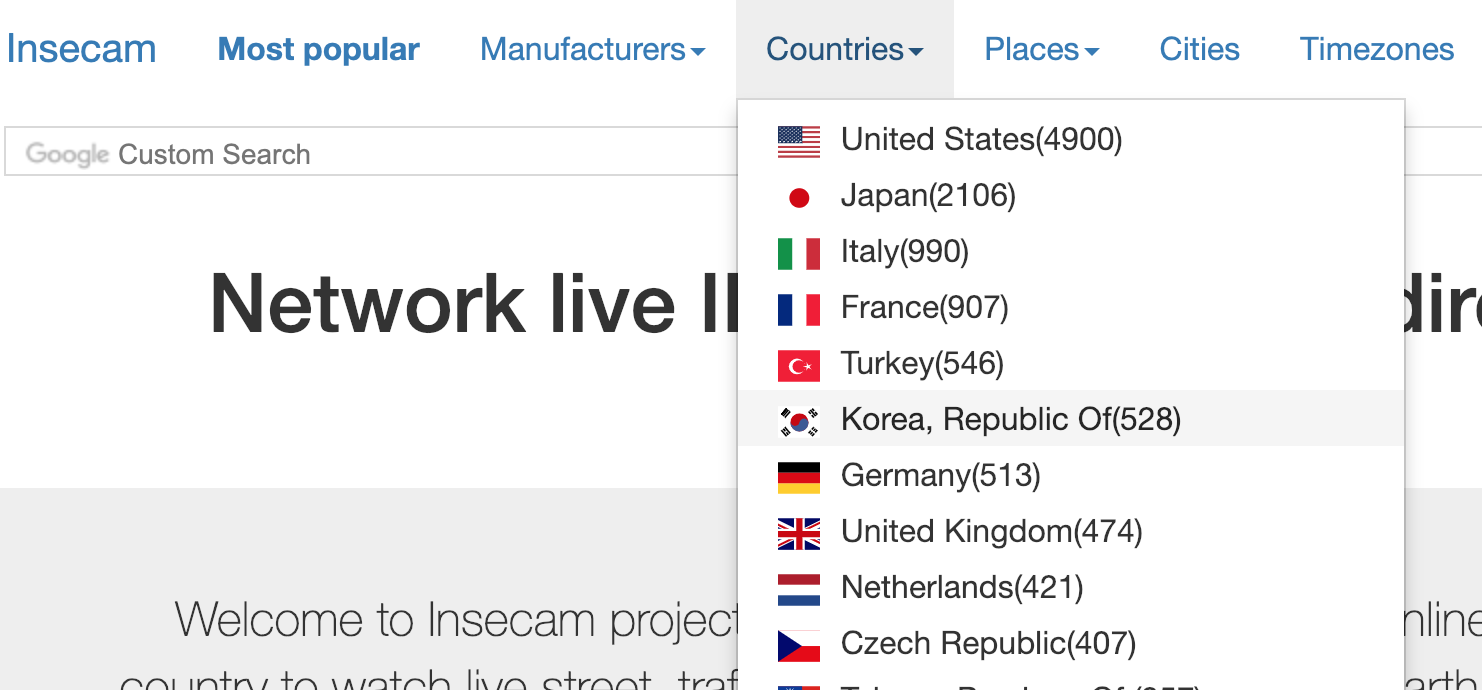
국가 단위로는 다음과 같이 제공이 되어서, 일단 국내단말만 추릴 수 있었다. 총 528개의 단말이 공개되어 있는 모양이다.
하지만 이 다음이 문제였다. 일단 제공되는 UI와 진리(?)의 소스보기와 요소검사를 통해 해당 페이지의 DOM 구조를 파악하자.
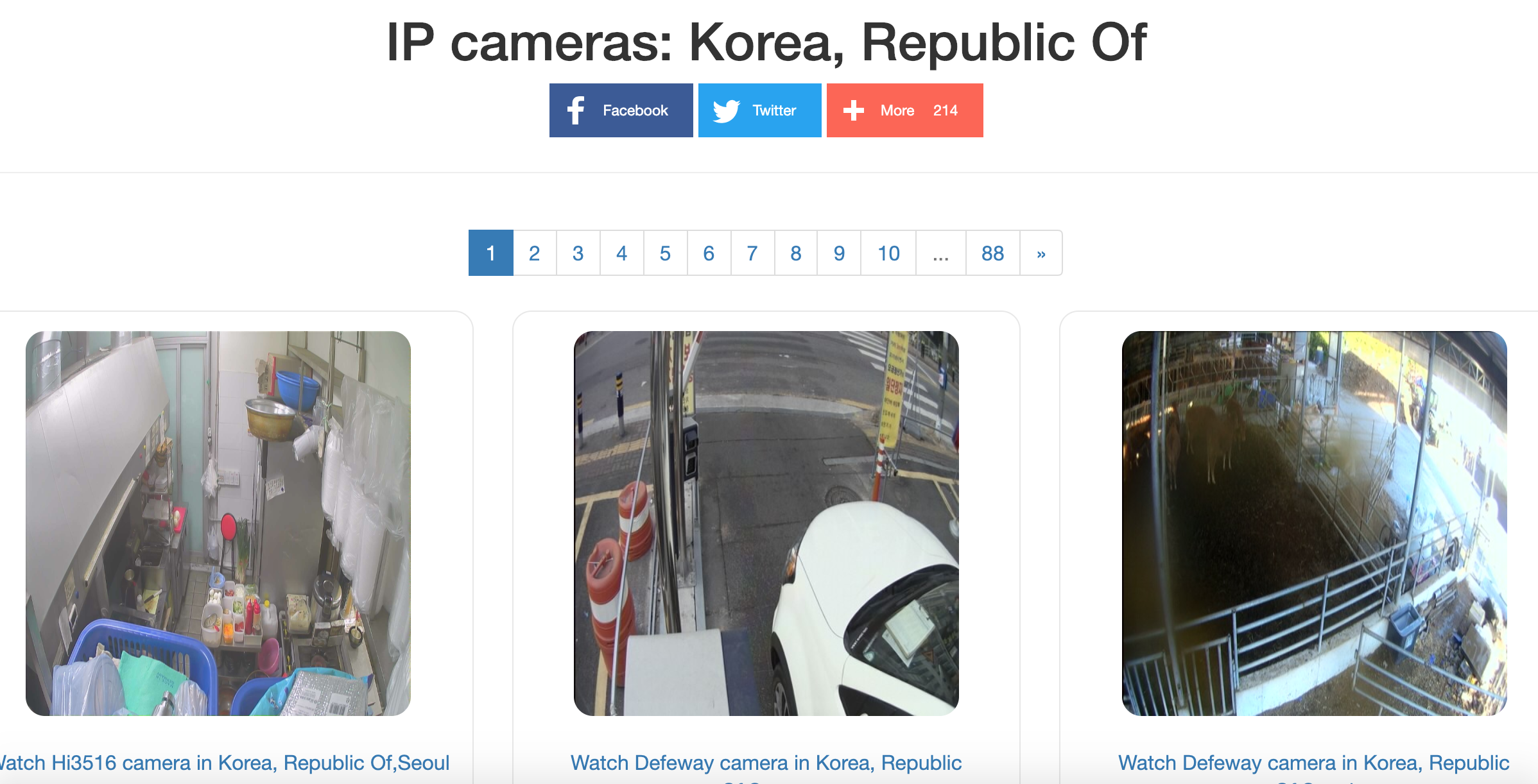
UI는 위와 같이 한 페이지에 6개의 화상 화면이 출력된다. 총 88페이지 까지 있다.
이것을 수동으로 소스보기에서 하나하나 IP와 URI를 따오기는 인고의 시간이다. 머신의 힘을 이용하길 하고 소스보기를 통해 패턴을 본다.
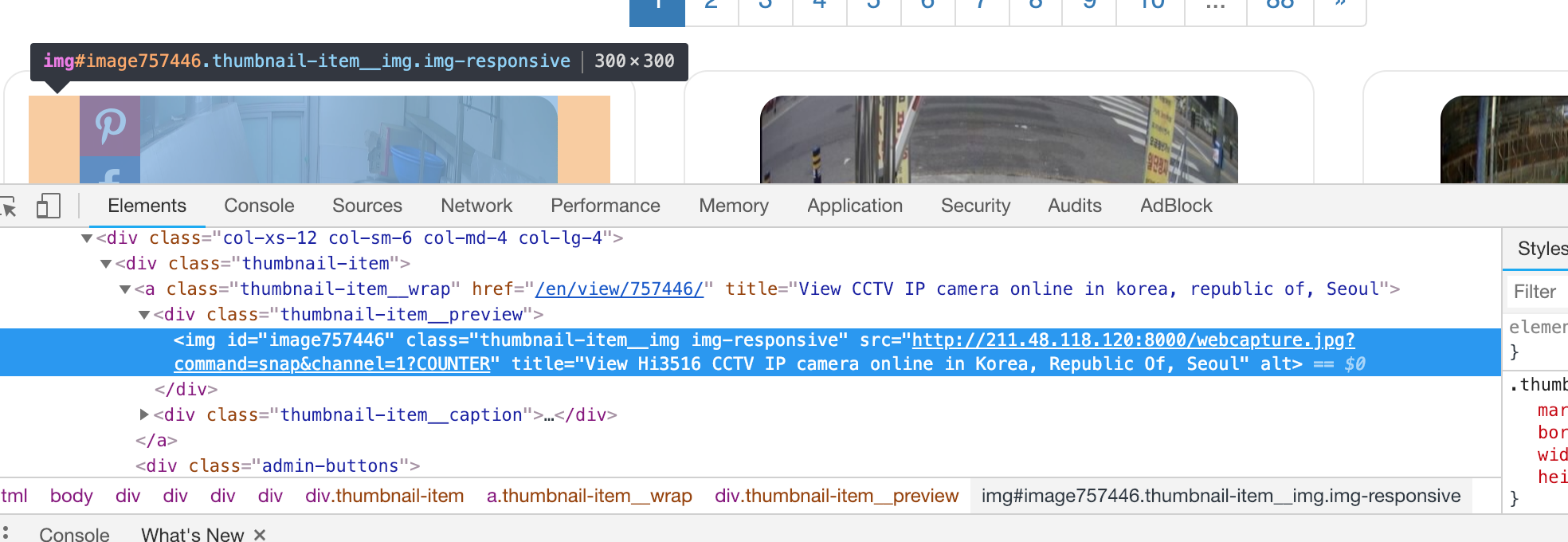
각자의 <div>에 <img> 엘리먼트 들이 들어있다. 어떻게 가져와야 할까 고민하던 도중 각자의 <img>가
thumbnail-item__img img-responsive라는 이름의 동일한 class를 가지고 있던것을 확인하였다.
이렇게 되면 선택자를 클래스명으로 가져오면 되기 때문에 얘기가 쉬워진다. 후딱 코드를 짜보았다.
#!/usr/bin/env python
import requests
from bs4 import BeautifulSoup
URL = "https://www.insecam.org/en/bycountry/KR/?page="
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.3'}
def get_html(url):
_html = ""
resp = requests.get(url, headers=headers)
if resp.status_code == 200:
_html = resp.text
print(resp.status_code)
return _html
if __name__ == "__main__":
f = open("kr_iplist.txt", 'w')
for i in range(1, 92):
page_url = URL + str(i)
print(page_url)
html = get_html(page_url)
soup = BeautifulSoup(html, 'html.parser')
myimgs = soup.find_all("img", class_="thumbnail-item__img img-responsive")
for cam_img in myimgs:
print(cam_img.get('src'))
f.write(cam_img.get('src')+'\r\n')
f.close()
페이지를 쭉쭉 돌면서 get request 요청을 통해 200 Code 응답 시에 해당 html페이지를 긁어온다.
이 후, BeautifulSoup의 html.parser를 통하여 thumbnail-item__img img-responsive라는 클래스의 img element를
모두 저장한다. 예상대로 라면 한 페이지에 6개씩이니 총 6개의 엘리먼트가 저장되고,
마지막에는 src value 값을 통해 IP와 URI 값을 가져와, txt 파일로 출력하는 것이다.
정리작업은 윈도우에서 할 것이기 때문에 개행문자를 \r\n으로 끝내야 줄바꿈이 보기좋게 된다.
헤더의 User-Agent 값을 임의로 지정한 이유는 지정을 하지 않고 코드를 돌릴시 405 Error를 뿌려댔다. 아마도 웹 사이트에서 무분별한 크롤링을 막기 위해 User-Agent를 검사하는 듯했다.
User-Agent를 대충 지정해주고 나니 성공적으로 200 OK 응답이 떨어지고 코드가 돌았다.
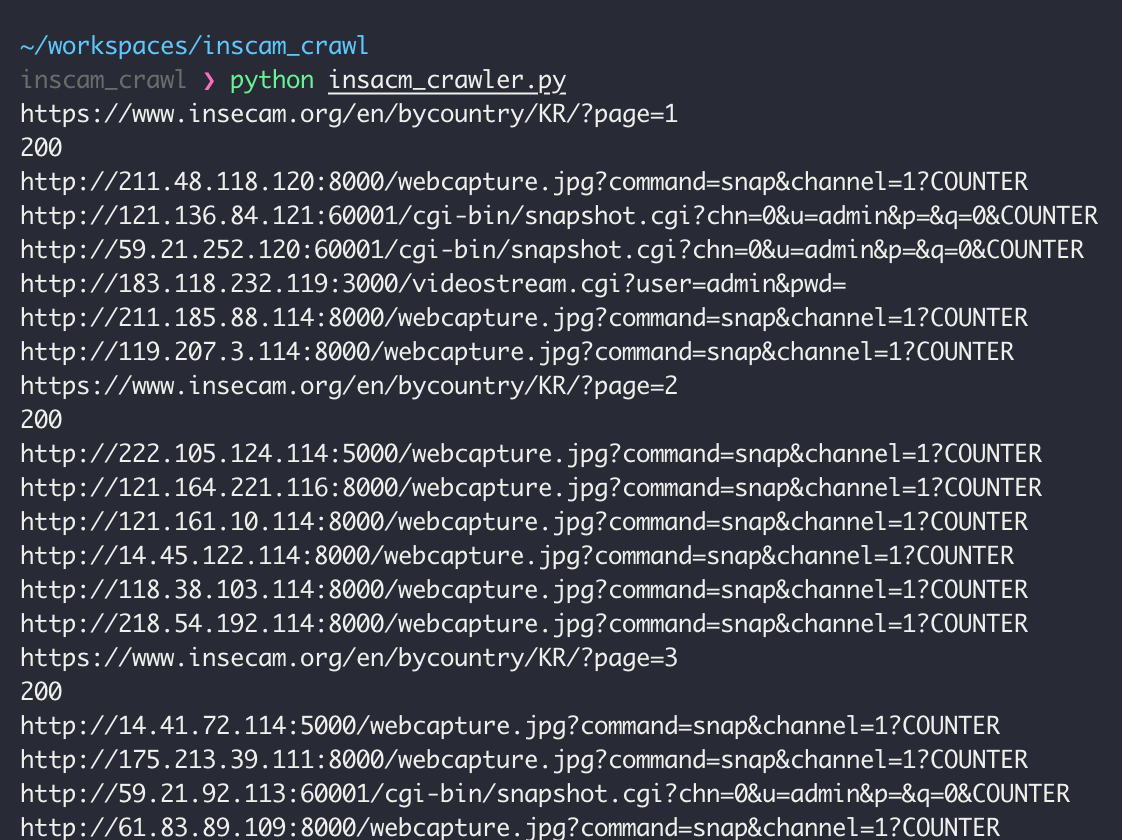
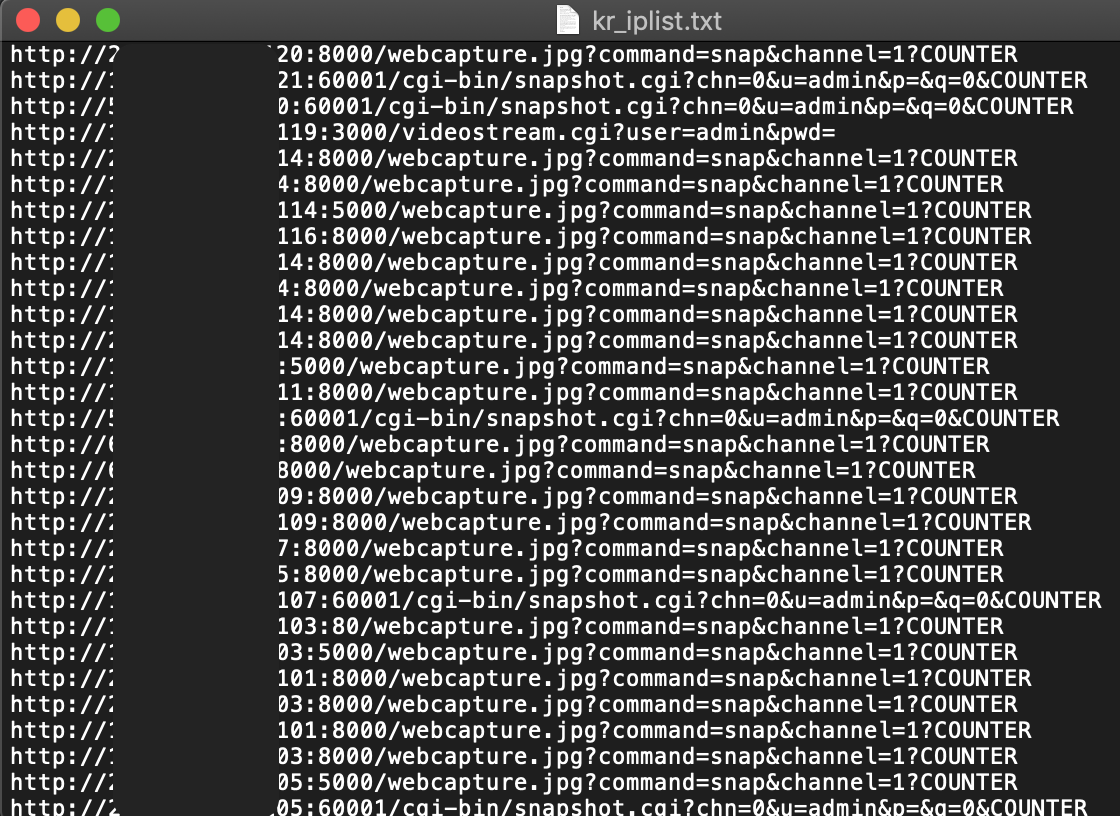
kr_iplist.txt 라는 파일로 떨궈져서 해당 파일을 열어보니 성공적으로 IP와 URI 리스트를 얻을 수 있었다.
openpyxl이나 xlrd등의 패키지를 이용하여서 정밀하게 엑셀로 출력하는 방법도 있을 것이다.
나는 급하게 리스트 확보가 중요하였기 때문에 그냥 txt로 작업을 하였다.
댓글남기기